# Tesseract & OpenCV
Tesseract와 OpenCV를 이용한 OCR(Optical Character Recognition)에 대해 알아보겠습니다.
테서랙트(Tesseract)는 다양한 운영체제에서 사용할 수 있도록 개발된 OCR 엔진입니다. 처음에 1985년에 HP연구소에서 개발되었던 소프트웨어가 2005년 오픈 소스로 출시 되었고 이후 2006년부터는 구글에서 후원하고 있다고 합니다. 현재는 버전 5까지 개발된 상태이며, 버전 4 기준 116개의 언어에 대해 문자 인식이 가능하다고 합니다.
본 포스팅에서는 윈도우와 파이썬 환경에서 테서랙트와 OpenCV를 이용하여 OCR을 수행하는 과정에 대해 다뤄보도록 하겠습니다.
먼저 윈도우 버전의 테서랙트를 설치하려면 테서랙트 깃허브에서 윈도우 버전을 다운받아 설치해야 합니다.

다운 받은 후 차례차례 설치하면 됩니다.
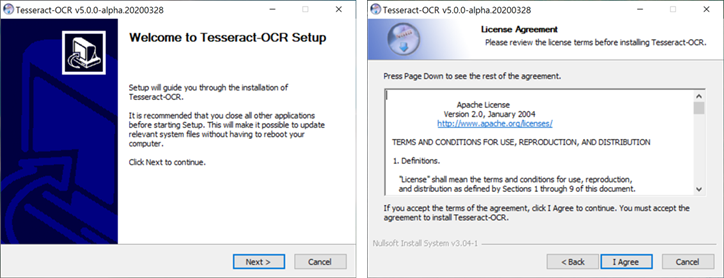
Apache License에 동의 후 설치를 진행하면 되는데, 영어외 다른 언어인식을 수행하려면 "Additional language data(download)"를 선택 후 원하는 언어를 체크한 이후에 설치를 진행해야합니다. 이때, 추가 언어 데이터는 설치를 진행하며 다운로드를 받기 때문에 인터넷이 연결되어 있어야 합니다.
설치가 완료되면 명령프롬프트(CMD)창에서 테서랙트를 어느 위치에서든지 사용할 수 있도록 환경변수를 설정해주어야합니다.
시스템 -> 고급시스템 설정 -> 고급 -> 환경변수
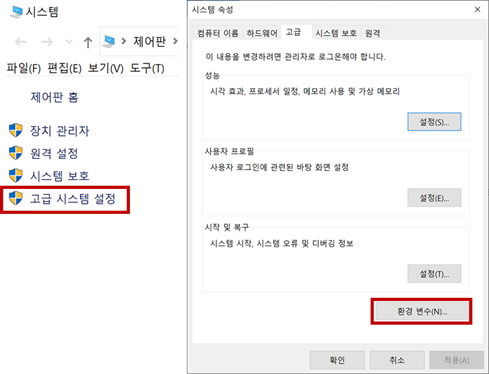
-> 시스템 변수 -> "Path" 선택 후 편집 -> 새로만들기 -> 테서랙트 설치 폴더 위치 등록
저의 경우 64비트로 설치하였기에 다음의 경로로 설치되었습니다. (C:\Program Files\Tesseract-OCR)

이후 명령프롬프트창에서 테서랙트를 이용하여 OCR을 수행할 수 있습니다. 명령어는 아래의 규칙으로 작성하시면 됩니다.

>> tesseract [이미지 파일명] [출력방식] [-l 언어선택] [--oem OCR엔진 모드] [--psm 페이지 분할 모드] ...등
[이미지 파일명]은 OCR을 수행할 이미지의 경로를 의미하고,
[출력방식] "stdout"을 입력할 경우 커맨드 창에서 바로 결과를 출력하고, 파일경로와 파일명을 입력하면 해당 위치에 text 파일로 저장됩니다.
[-l 언어선택]은 "-l kor", "-l eng", "-l kor+eng" 등과 같이 언어 인식을 수행할 언어를 선택합니다.
[--oem OCR엔진 모드]과 [--psm 페이지 분할 모드]는 아래 그림에서 볼 수 있는 것처럼 OCR을 수행할 엔진과 페이지 분할 방식을 선택할 수 있습니다.(아래 내용은 CMD창에 "tesseract --help-extra" 를 입력하면 확인할 수 있습니다.)

이전에 포스팅하였던 독서 리뷰 "오늘부터의 세계" 책 표지를 한국어로 인식한 결과를 확인해보겠습니다.
>> tesseract world1.tif world1 -l kor (world1.tif는 test 폴더 안에 넣어 두었습니다)
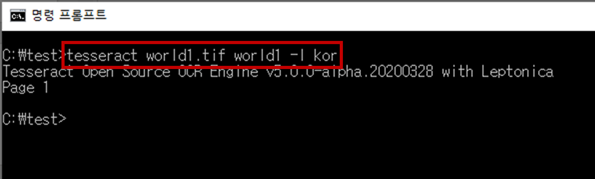
중간에 가로로 되어있는 글자도 인식하였고, 윗부분 보라색 배경의 글씨들을 제외하고는 그리고 "원톄쥔"을 "원톄"로만 잘못 인식한 것 말고는 거의 정확하게 인식한 것을 확인할 수 있었습니다.

다음은 파이썬 환경에서 테서랙트를 사용하는 것을 살펴보겠습니다.
먼저, pypi.org에서 pytesseract를 설치해야 합니다. 명령프롬프트창에서 >>pip install pytesseract 을 입력하여 테서랙트 라이브러리를 설치합니다. pytesseract는 tesseract를 래핑(wrapping)한 라이브러리이기 때문에 위에서 안내한 것처럼 tesseract를 설치한 이후에 사용할 수 있습니다.
위에서 사용했던 이미지를 사용하여 OCR을 파이썬 환경에서 수행해보겠습니다.
먼저, pytesseract를 import 합니다.

이후, pytesseract.image_to_sting("이미지", lang="언어", config="--oem 번호, --psm 번호") 명령어를 이용하여 이미지 내의 문자열을 출력할 수 있습니다. 아래 테스트에서는 custom_config에 --oem 3(OCR 엔진 3번), --psm 3(페이지 분할 모드 3번)을 선택하였지만 사실 OCR 엔진 3번, 페이지 분할 모드 3번이 기본값으로 설정되어 있습니다.
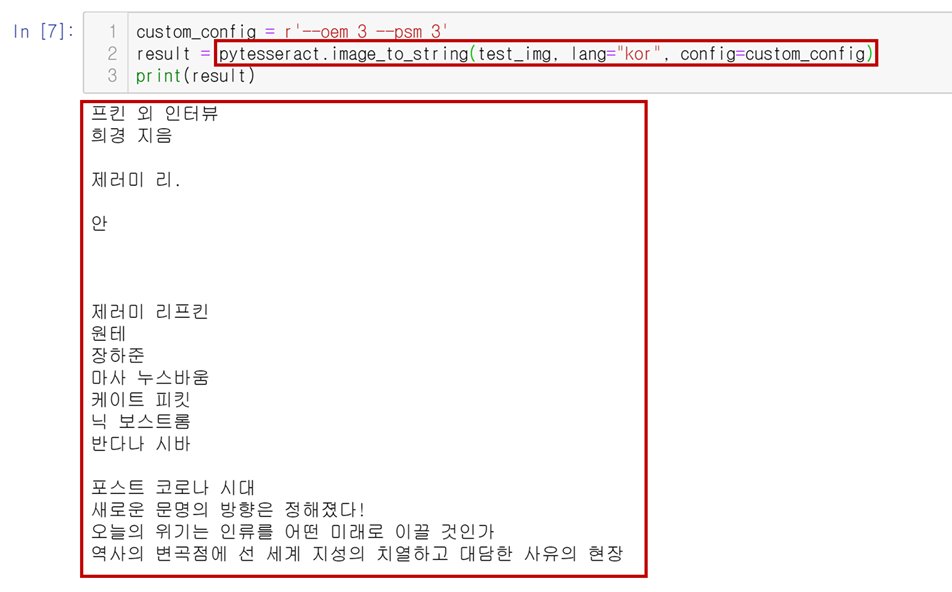
테스트 결과 앞서 명령프롬프트에서 실행한 것과 유사한 결과가 나왔습니다. 다만 세로 문자열의 순서가 조금 뒤바뀌어 나온것을 보니 가로방향으로 문자를 인식하는 것 때문이라는 생각이 듭니다. 자세한 것은 내부를 더 들여다 봐야 할 것 같습니다. 다음 포스팅에서는 문자 인식률을 높이기 위한 전처리(pre-processing)와, 출력된 문자열의 활용을 위한 후처리(post-processing)에 대해 다뤄보겠습니다.
<Reference>
- https://github.com/UB-Mannheim/tesseract/wiki
- https://en.wikipedia.org/wiki/Tesseract_(software)
- https://ko.wikipedia.org/wiki/%ED%85%8C%EC%84%9C%EB%9E%99%ED%8A%B8
- https://nanonets.com/blog/ocr-with-tesseract/
- https://pypi.org/project/pytesseract/
- https://github.com/tesseract-ocr/tesseract/blob/master/README.md
'Data science > Image data' 카테고리의 다른 글
| [Tesseract & OpenCV]를 이용한 OCR-2-2 전처리(pre-processing) (0) | 2020.08.22 |
|---|---|
| [Tesseract & OpenCV]를 이용한 OCR-2-1 전처리(pre-processing) (0) | 2020.08.18 |

