#VOSviewer
VOSviewer는 Web of science나 Scopus, Pubmed 등의 사이트에서 서지정보를 추출하여 분석을 수행할 수도 있고, Scopus나 Microsoft Academic의 API를 연동하여 프로그램에서 직접 서지정보를 가져와서 분석을 수행할 수도 있습니다. 물론 저널 구독이나 계정 가입이 필요합니다. 이와 관련한 자세한 내용은 메뉴얼을 참고해주세요. 오늘 포스팅에서는 Sciencedirect에서 COVID-19관련 연구들의 키워드 분석을 수행해보겠습니다. Sciencedirect에서 논문을 검색하려면 계정 가입과 로그인이 필요합니다.
로그인 후, "COVID-19"를 키워드로 자료를 검색해보았습니다. 무려 19,418개의 자료가 검색되네요.

검색된 자료에서 논문과 학회자료들로 필터링을 하였습니다.

필터링 하였더니 2019년부터 2021년까지 9,208개의 자료가 남았군요. 이 자료들을 전부 분석하기에는 많을 것 같아 1,000개만 추려서 분석해보도록 하겠습니다.

자료들을 한번에 100개씩 볼 수 있도록 설정을 변경한 후 전체선택하고 "Export"를 누르면 아래와 같은 창이 나타납니다. VOSviewer는 아래 4가지 타입의 자료를 이용하여 모두 분석을 수행할 수 있는데요, 저는 RIS type으로 서지정보를 추출하였습니다.

자료를 추출 후 VOSviewer의 Action pannel에서 "Create"를 눌러 map 만들기를 시작합니다. 지난 포스팅에서는 network data예제 파일이 있어서 그 파일로 바로 분석을 수행하였는데요, 이번에는 Sciencedirect에서 직접 추출한 서지정보를 이용할 것이기 때문에 두번째 tab(Create a map based on bibliographic data)을 선택합니다.
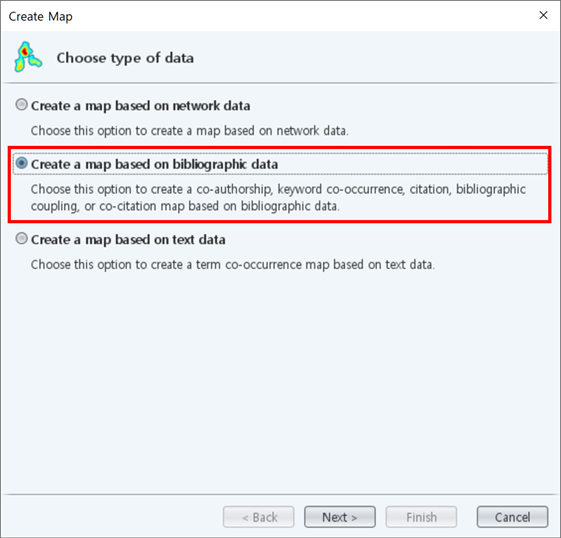
제가 추출한 파일 형식은 RIS type의 파일이기 때문에 아래 두번째 tab(Read data from reference manager files)를 선택합니다.

Sciencedirect에서 100개씩 Export한 서지정보 파일을 모두 선택합니다. VOSviewer는 파일 복수 선택이 가능하도록 되어있습니다.

크게 두가지 분석을 수행할 수 있는데요, 선택된 data에서 공저자에 관한 네트워크 분석을 수행하는 것(Co-authorship)과 키워드 등장 빈도가 높은 것을 기준(Co-occurrence)으로 네트워크 분석을 수행할 수 있습니다.
저자나 키워드의 빈도를 체크하는 방법은 "Full counting"과 "Fractional counting"이 있는데요, Full counting은 말 그대로 표면적인 빈도를 그대로 반영하는 것이고, Fractional counting은 일종의 정규화를 해주는 방법입니다.

다음으로 키워드가 등장하는 빈도의 최소값을 설정하여 필터링을 수행할 수 있습니다. 이 값을 너무 작게하면 너무 많은 자료가 나타나서 분석을 어렵게 할 수도 있고, 너무 크게하면 너무 많은 자료가 누락될 가능성이 있으니 적정한 값을 수정해가며 선택하는 것이 필요합니다. 저는 일단 최소 5번이상 등장하는 키워드들을 가지고 분석을 수행해보겠습니다.

필터링을 수행하니 105개의 키워드가 선택된다고 하네요. 여기서 한번 더 추릴 수 있습니다. 선택된 키워드의 개수를 조정할 수 있는데 이 값을 줄이면 빈도가 낮은 것부터 한번 더 걸러지게 됩니다.

아래와 같이 map을 그려주기 전에 선택된 키워드들과 그 정보들을 보여주네요. "COVID-19", "sars-cov-2", "coronavirus"는 모두 같은 것을 의미하지만 문헌들마다 다르게 사용되었고, COVID-19라는 명칭도 발병된 후 시일이 지난 다음에 명칭이 통일된 것이니 일단 거르지 않고 모두 네트워크 map을 그리는데 사용하겠습니다.

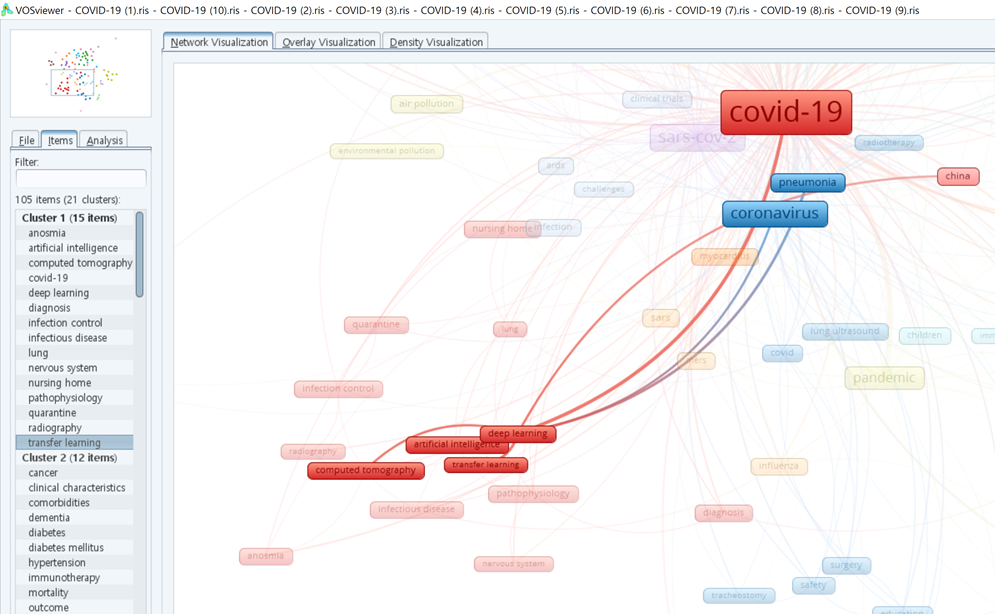
아래와 같이 네트워크 map이 그려졌습니다. 빈도가 가장 높게 나왔던 "COVID-19"가 가장 크게 나타나고 있습니다. 왼쪽에 Action pannel의 "Items" 탭을 보면 클러스터별로 분류된 것을 볼 수 있습니다.

Map을 그리기전 필터링 하지 않았던 것처럼 같은 것을 의미하는 "COVID-19", "sars-cov-2", "coronavirus"는 모두 등장하였네요. 각각을 살펴보면 다른 키워드들과 연결된 것이 유사한 것을 볼 수 있었습니다.

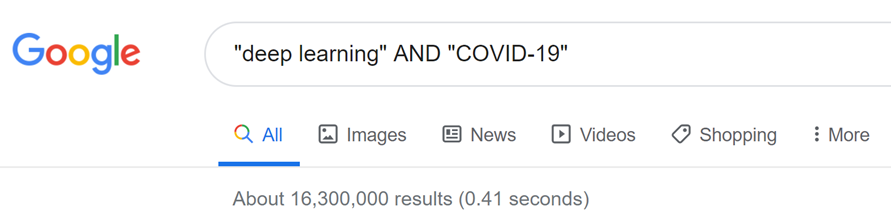
클러스터 1를 살펴보면 "deep learning", "artificial intelligence", "transfer learning", "computed tomography"와 같은 키워드가 보이네요. 아마도 COVID-19를 진단하는데 딥러닝을 이용하여 CT나 MRI 같은 이미지 자료를 분석하는 것으로 예상됩니다.
실제로 구글에 "deep learning"과 "COVID-19"를 검색해보니 자료가 16,300,000개나 검색이 되네요.
다음으로 클러스터 2를 살펴보겠습니다. "diabetes(당뇨)", "mortality(사망)", "hypertension(고혈압)", "comobidities(동반질병)"과 같은 단어들이 보입니다. COVID-19가 당뇨나 고혈압과 같은 기저질병이 있는 사람에게 더 취약하거나 혹은 다른 연관성들이 있어서 관련 키워드로 함께 나타난 것 같은데요,
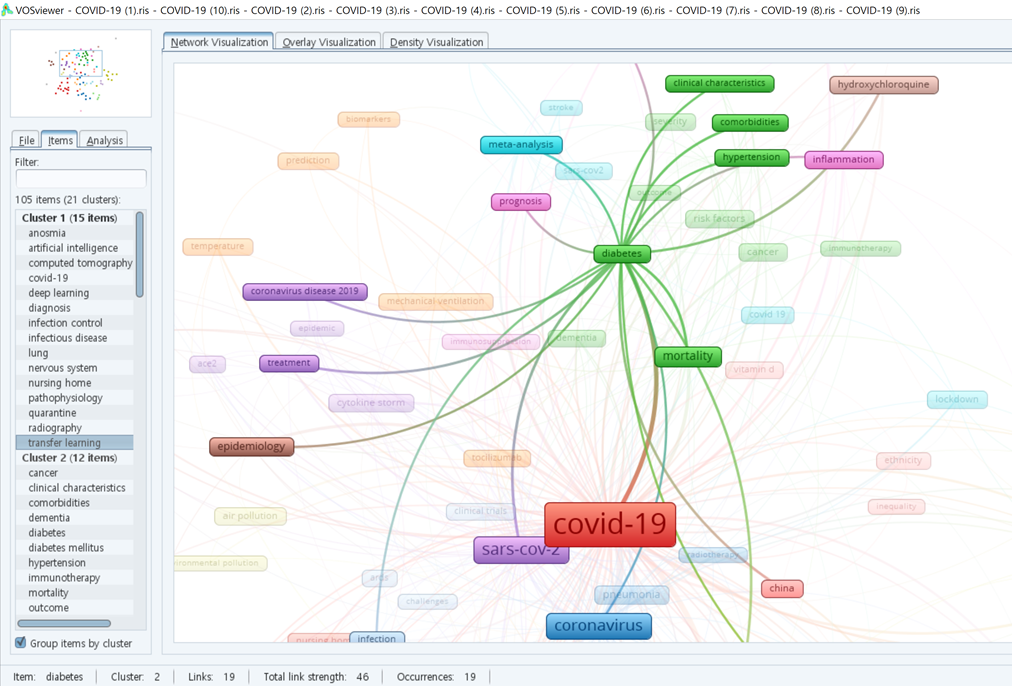
실제로 "COVID-19"와 "diabetes", "hypertension"을 함께 검색해보니 각각 3억 8천만, 6천 2백 5십만개의 검색결과가 나왔습니다.

또 고혈압과 당뇨환자에게 더 치명적이라는 뉴스기사도 있었습니다.
https://www.hankookilbo.com/News/Read/A2020082914350003923
국내 코로나19 사망자 97%가 고혈압ㆍ당뇨 등 기저질환
국내 신종 코로나바이러스 감염증(코로나19) 사망자의 97%가 고혈압ㆍ당뇨병 등 기저질환이 있었던 것으로 조사됐다. 코로나19에 걸린 80대 이상 고령 환자는 10명 중 2명이 사망한 것으로 나타났��
www.hankookilbo.com
다음으로는 클러스터 4를 살펴보면 "fear", "anxiety", "depression", "stress"와 같은 단어들이 보이네요. 또 이 단어들은 "COVID-19"와 "coronavirus", "pandemic"과 같은 단어와 연결되어 있습니다.

다음으로는 "Overlay visualization"을 살펴보겠습니다. 여기서 "Scores"는 발행년도를 기준으로 키워들의 색상이 반영되었는데요, 분석에 사용된 논문들은 2019-2021년 3개년치 밖에 사용되지 않았기 때문에 색상차이가 뚜렷하게 나타나지는 않았습니다.
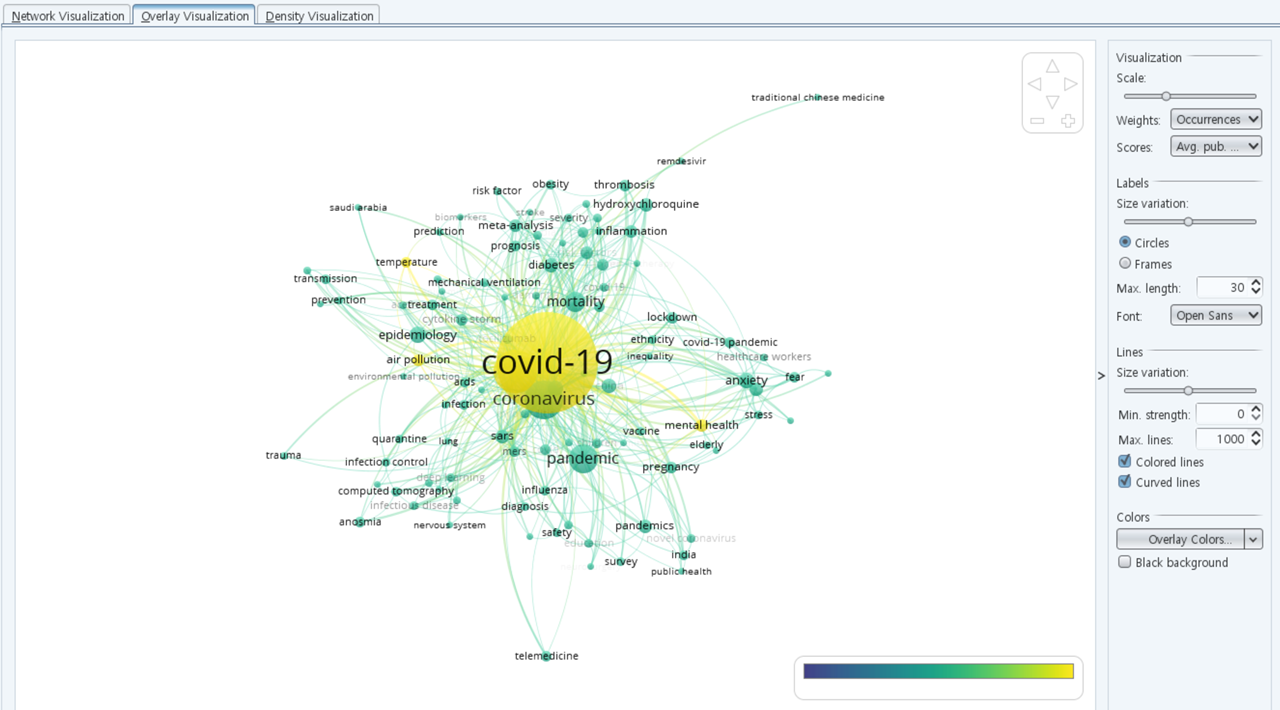
마지막으로 키워드별 밀도맵(Density visualization)를 살펴보면 아래와 같습니다.

분석한 내용을 저장하려면 Action pannel에서 "Save"를 눌러 아래와 같이 "map"파일과 "network"파일을 따로 저장할 수 있습니다. 아래 저장된 파일을 이용하면 다음번에 불러올때는 위에서 10개의 RIS 파일을 불러올 필요없이 아래의 map, network 파일만으로 다시 분석을 수행할 수 있습니다.

<Reference>
- https://www.sciencedirect.com/
- https://www.hankookilbo.com/News/Read/A2020082914350003923
- https://www.vosviewer.com (공식홈페이지)
- https://seinecle.github.io/vosviewer-tutorials/generated-html/importing-en.html (Tutorial)
- https://www.vosviewer.com/documentation/Manual_VOSviewer_1.6.8.pdf (Manual)
- https://seinecle.github.io/vosviewer-tutorials/
'유용한 Tool' 카테고리의 다른 글
| [VOSviewer]를 이용한 키워드 네트워크 분석 1 (0) | 2020.08.28 |
|---|
